Class HierarchicalGraph
Holds a hierarchical graph to speed up certain pathfinding queries.
A common type of query that needs to be very fast is on the form 'is this node reachable from this other node'. This is for example used when picking the end node of a path. The end node is determined as the closest node to the end point that can be reached from the start node.
This data structure's primary purpose is to keep track of which connected component each node is contained in, in order to make such queries fast.
A connected component is a set of nodes such that there is a valid path between every pair of nodes in that set. Thus the query above can simply be answered by checking if they are in the same connected component. The connected component is exposed on nodes as the Pathfinding.GraphNode.Area property and on this class using the #GetArea method.
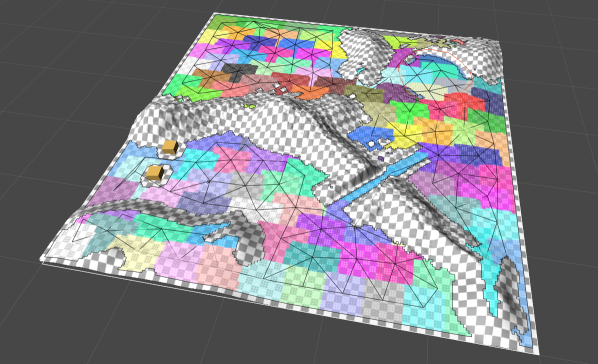
In the image below (showing a 200x200 grid graph) each connected component is colored using a separate color. The actual color doesn't signify anything in particular however, only that they are different. 
Prior to version 4.2 the connected components were just a number stored on each node, and when a graph was updated the connected components were completely recalculated. This can be done relatively efficiently using a flood filling algorithm (see https://en.wikipedia.org/wiki/Flood_fill) however it still requires a pass through every single node which can be quite costly on larger graphs.
This class instead builds a much smaller graph that still respects the same connectivity as the original graph. Each node in this hierarchical graph represents a larger number of real nodes that are one single connected component. Take a look at the image below for an example. In the image each color is a separate hierarchical node, and the black connections go between the center of each hierarchical node.
With the hierarchical graph, the connected components can be calculated by flood filling the hierarchical graph instead of the real graph. Then when we need to know which connected component a node belongs to, we look up the connected component of the hierarchical node the node belongs to.
The benefit is not immediately obvious. The above is just a bit more complicated way to accomplish the same thing. However the real benefit comes when updating the graph. When the graph is updated, all hierarchical nodes which contain any node that was affected by the update is removed completely and then once all have been removed new hierarchical nodes are recalculated in their place. Once this is done the connected components of the whole graph can be updated by flood filling only the hierarchical graph. Since the hierarchical graph is vastly smaller than the real graph, this is significantly faster.
So finally using all of this, the connected components of the graph can be recalculated very quickly as the graph is updated. The effect of this grows larger the larger the graph is, and the smaller the graph update is. Making a small update to a 1000x1000 grid graph is on the order of 40 times faster with these optimizations. When scanning a graph or making updates to the whole graph at the same time there is however no speed boost. In fact due to the extra complexity it is a bit slower, however after profiling the extra time seems to be mostly insignificant compared to the rest of the cost of scanning the graph.
Inner Types
Public Methods
Marks this node as dirty because it's connectivity or walkability has changed.
Get the connected component index of a hierarchical node.
Data about the hierarhical nodes.
Schedule a job to recalculate the hierarchical graph and the connected components if any nodes have been marked as dirty.
Must be called after a job that uses GetHierarhicalNodeData has been scheduled.
Disposes of all unmanaged data and clears managed data.
Recalculate everything from scratch.
Recalculate the hierarchical graph and the connected components if any nodes have been marked as dirty.
Public Variables
Private/Protected Members
Holds areas.Length as a burst-accessible reference.